现在开源的ai大模型越来越多,比如:LLama,通义千问,gemma2等,但这些模型想要优质的回答就非常吃电脑配置,如果是轻量工作,建议还是部署参数少的开源版本,比如这次我尝试在自己的笔记本上部署阿里的Qwen2-7B的版本。
部署环境
- 电脑配置:32GB内存,CPU为AMD7840HS,显卡为780M,硬盘空间为1T
- 部署方式:电脑本地部署
- 部署环境:Windows10
- 部署模型:Qwen2-7B版本
- AI模型管理工具:ollama
- AnythingLLM
安装Ollama与AnythingLLM
- ollama安装地址
1
https://ollama.com/
安装完毕后,我们需要设置下文件下载部署的路径,不然后面模型默认下载到C盘。步骤如下:
高级系统设置->环境变量->系统变量->点击”新建”来创建一个变量,变量名为:”OLLAMA_MODELS”,变量值为:”D:\AIModules”。这里D:\AIModules为我们想要下载部署的文件位置,各位可以根据自己的情况进行修改哦!->设置完成后,点击确定,保存即可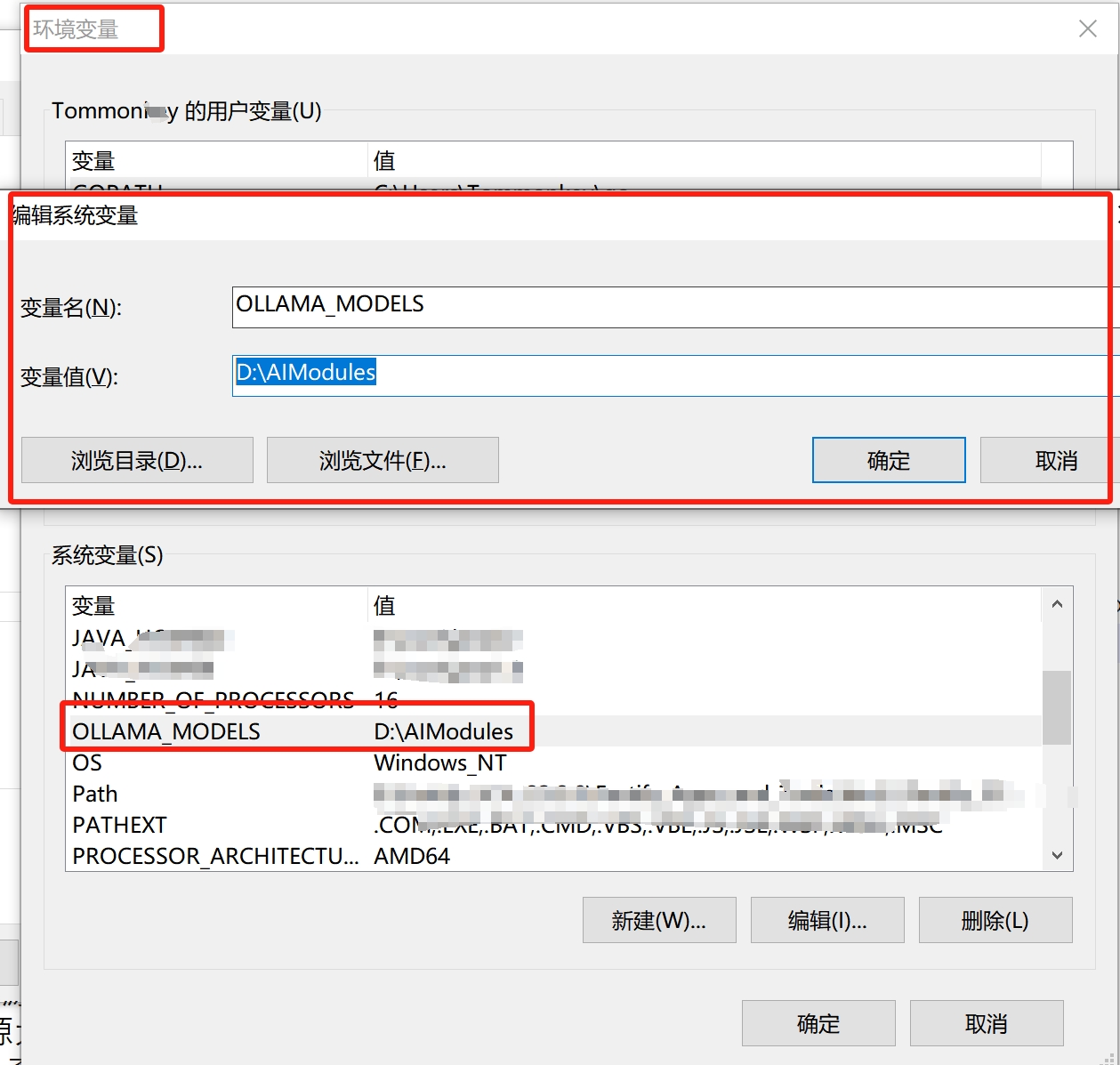
- AnythingLLM安装地址
1
https://anythingllm.com/
各位根据自己的系统下载相应的发行版本安装即可
选择AI模型下载
通过ollama可以非常方便的下载我们想要的开源模型和相应版本。首先访问ollama moldel页面挑选自己想要的模型
比如我们想部署qwen2-7b模型,就点击进去,查看ollama部署该版本的命令,并复制在本地执行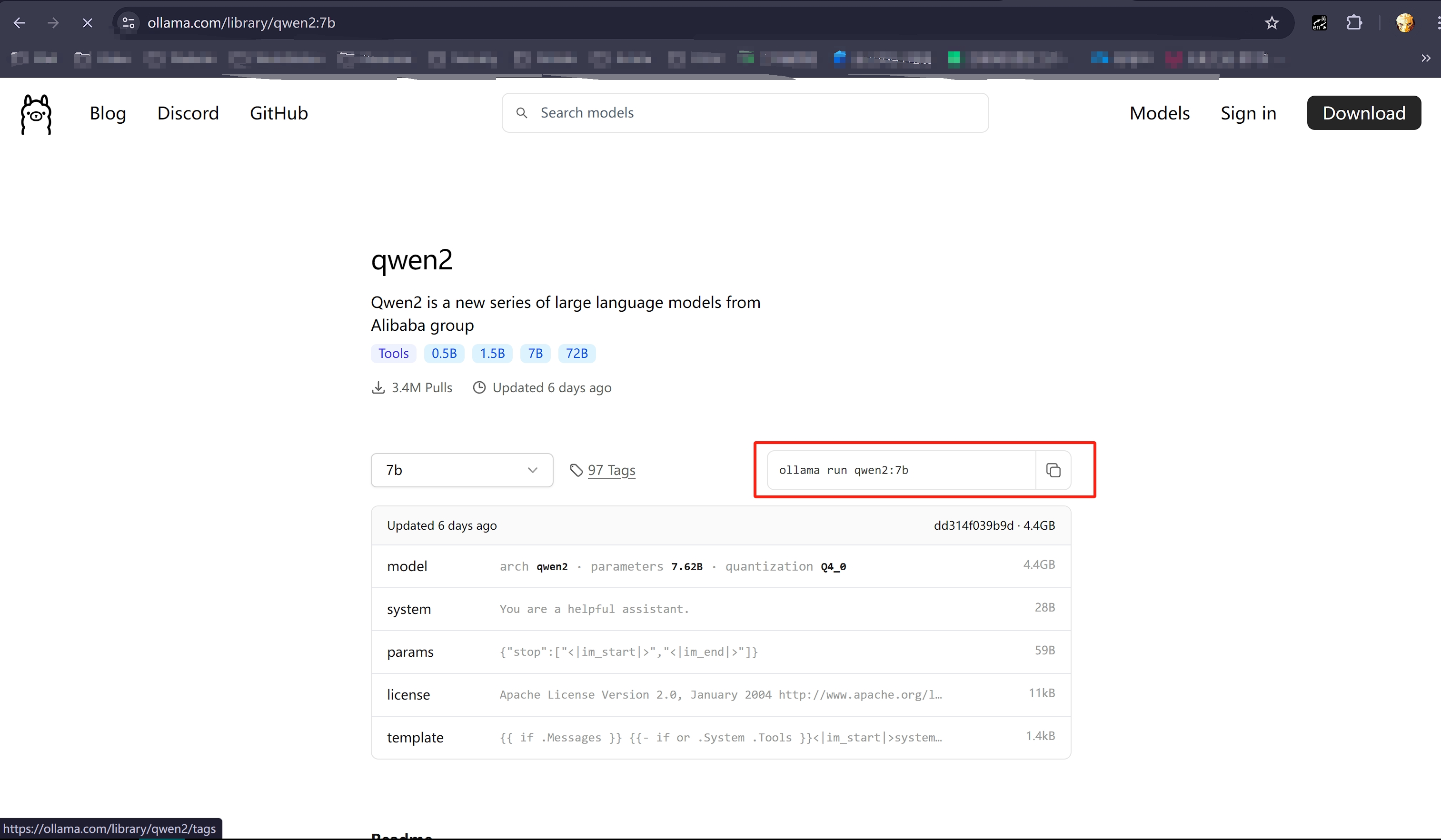

静静的等待下载完成部署,就可以通过cmd进行对话了!这里我下载部署完毕后,问了一个“如何在windows上安装pip?”的问题,给出的回答还是可以的,同时在模型回答问题的时候查看配置消耗情况,发现cpu峰值占用在65%左右,内存也差不在55%左右。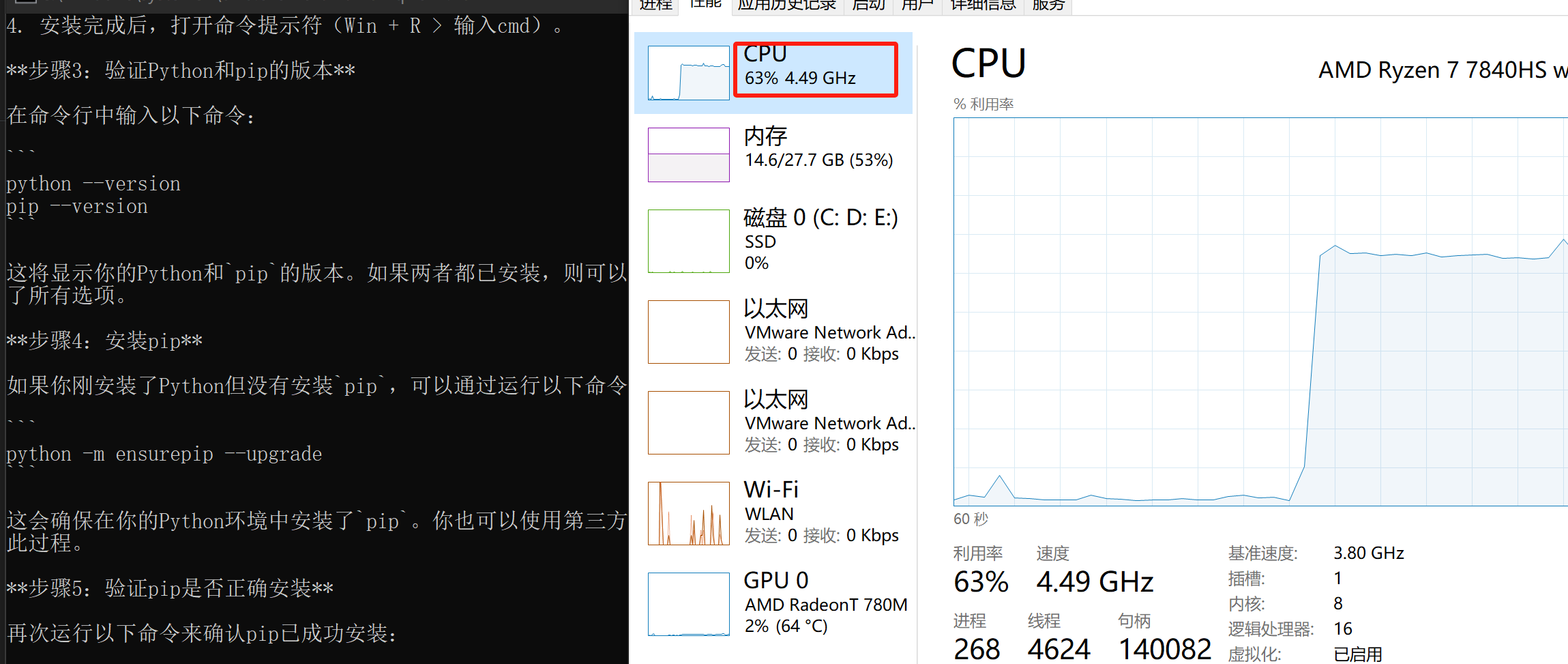
使用AnythingLLM可视化对话
点击启动我们之前安装好的AnythongLLM,创建新工作区,随便取一个名字,比如”qwen2-7b”。然后,点击设置->聊天设置->将工作区LLM提供者选择为Ollama,工作区聊天模型为qwen2-7b->点击代理设置,同样的将工作区代理LLM提供商设置为Ollama,工作区代理为qwen2-7b,保存即可。
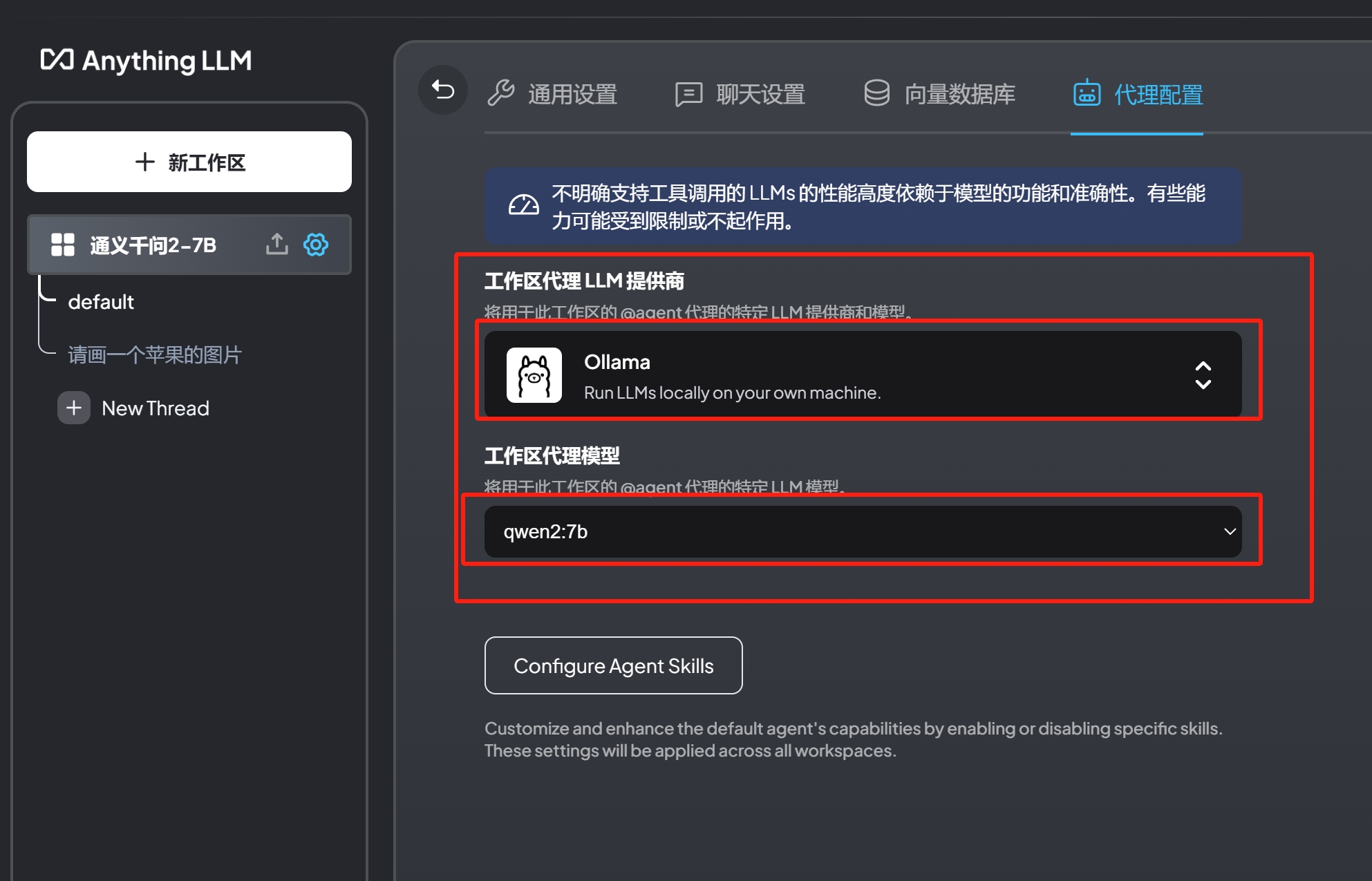
实战效果
下图为实战效果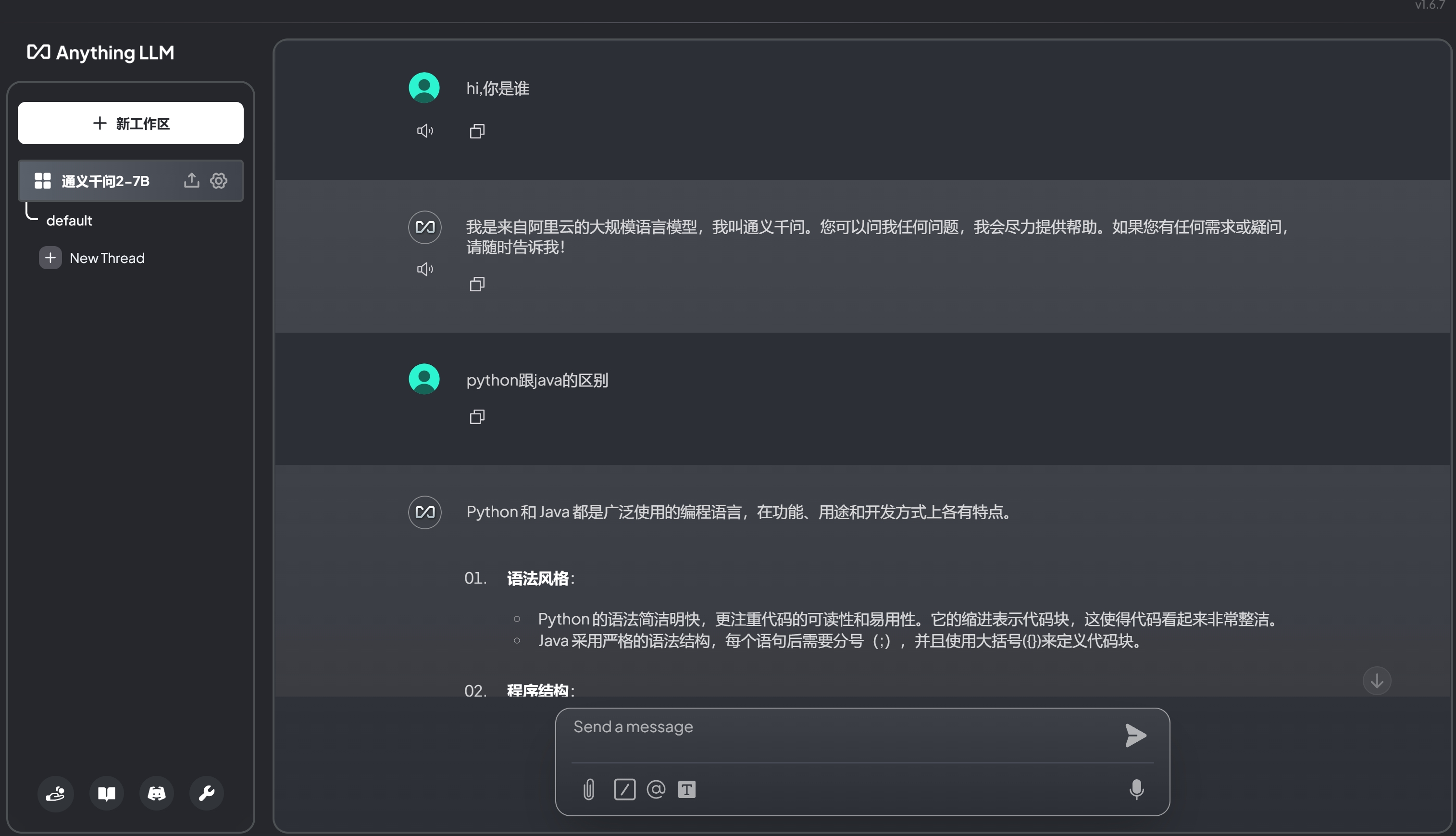
总结:日常轻度任务够用,复杂问题会出错,不够聪明,毕竟是7b版本!

